Linux 文件系统排查指南
Linux 存储堆栈
图片是 Linux 存储栈一般分为 3 层:文件系统层,块层,设备层。
下图展示了存储栈的结构,并使用不同颜色区分各组成部分:
- 天蓝色: 硬件存储设备,K1 涉及到的 mmc、SD、U 盘、SSD、SATA 硬盘
- 橙色: 传输协议层
- 蓝色: Linux 系统中的设备文件
- 真正硬件设备 (sda(硬盘)、mmc、nvme 等)
- 虚拟块设备 (loop、zram)
- 黄色: I/O调度策略(noop、deadline、CFQ)
- 绿色: Linux 文件系统
- 蓝绿色: Linux Storage 操作的基本数据结构 BIO
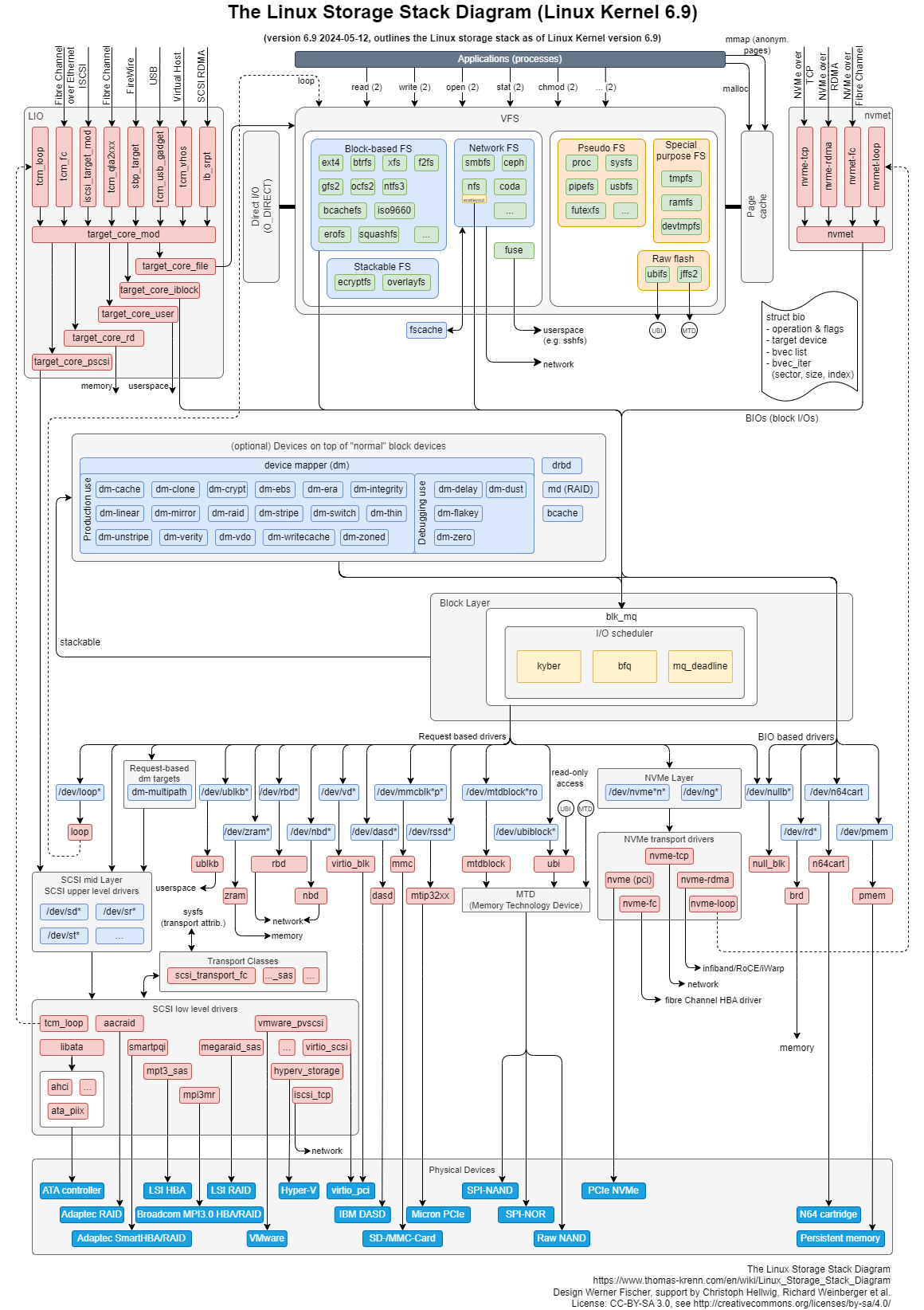 上述图片来源:Thomas-Krenn AG,来源链接,版权声明:本图仅用于技术说明,版权归原作者所有
上述图片来源:Thomas-Krenn AG,来源链接,版权声明:本图仅用于技术说明,版权归原作者所有
Linux 回写
由于硬盘读写速度远低于内存,为了避免每次文件操作都直接访问硬盘,Linux 内核采用 页缓存(Page Cache)机制 来缓存文件数据。
- 几乎所有文件 I/O 都依赖缓存,除非在打开文件时使用
O_DIRECT标志。 - 缓存提高读写性能,但可能带来掉电丢数据风险:调用
fwrite或write并不保证数据真正写入存储设备。
数据回写有两种方式:
- 主动同步回写
- 异步后台回写
主动同步回写
- 调用
write只是把数据提交到内核的 Page Cache(假设没有启用 Direct I/O)。 - 要确保真正写入存储设备,必须使用
fdatasync或fsync系�统调用。 - 除了内核空间有 Page Cache,C 库层也有自己的缓存,需要先
fflush把数据回写到下一层,也就是内核的 Page Cache,再调用fsync刷到物理设备。
系统支持的 sync 接口区别
| 接口 | 作用范围及颗粒度 |
|---|---|
flush | 用于 C 库的缓存刷入内核 |
fdatasync | 确保单个文件的数据回写,追求更高性能,也就是涉及到文件属性不保证回写,包括文件最后修改时间属性等 |
fsync | 仅用于回写单个文件,从内核 Cache 刷入磁盘,包括文件的数据和所有属性 |
sync | 确保整个系统缓冲区(脏页)排入写入队列,调用后立即返回 |
被动回写
Linux 内核会周期性触发异步回写线程,步骤如下:
Step 1: 内核按 dirty_writeback_centisecs 的时间间隔唤醒回写线程
Step 2: 回写线程会遍历 Page Cache 寻找那些被标记为脏的时间超过 dirty_expire_centisecs 的页面,并全部回写
Step 3: 回写线程接着会判断脏数据总量是否超过 dirty_background_ratio(单位是百分比)或 dirty_background_bytes�,如果超过则回写所有脏数据
Step 4: 回写线程等待下次唤醒周期
相关配置参数
| 配置文件 | 功能 | 默认值 |
|---|---|---|
dirty_background_ratio | 脏页总数占可用内存的百分比阈值,超过后唤醒回写线程 | 10 |
dirty_background_bytes | 脏页总量阈值,超过后唤醒回写线程 | 0 |
dirty_ratio | 脏页总数占可用内存的百分比阈值,超过后pause进程 | 20 |
dirty_bytes | 脏页总量阈值,超过后pause进程 | 0 |
dirty_expire_centisecs | 脏数据超时回写时间(单位:1/100s) | 3000 |
dirty_writeback_centisecs | 回写进程定时唤醒时间(单位:1/100s) | 500 |
Linux 数据预读
预读分为 同步预读 和 异步预读。
在 Linux 系统中,默认情况下不管是用户态调用 read,还是内核态调用 vfs_read,都会触发数据预读,即提前将一部分数据加载到 Page Cache 中。
- 顺序读加速: 通过扩大预读窗口(
ra->size),逐步增加预读量,典型场景如日志文件读取 - 随机读抑制: 当检测到非连续访问模式时,会自动收缩预读窗口
查看默认预读大小(单位:512B扇区)
cat /sys/block/sda/queue/read_ahead_kb
编程层优化:
- 使用
posix_fadvise()显式声明访问模式 - 对顺序访问文件设置
POSIX_FADV_SEQUENTIAL标志
性能测试
Fio
源码
源码地址:https://github.com/axboe/fio
可以自行下载源码并编译,或者在OS上自行安装,bian-linux默认已集成该工具
常用参数
- time
runtime=time
告诉fio在指定的时间段后终止处理。当省略单位时间,该数值以秒为单位进行解释,也可以直接配置runtime=24h,一般用于读写老化场景
time_based
如果设置,即使文件被完全读取或写入,fio也将在指定的运行期间运行。它会在runtime准许时间内多次循环相同的工作负载。一般用于读写老化场景
- I/O tpye
direct=bool
是否使用 direct io,测试过程不使用OS 自带的buffer,使结果更真实。
rw=randwrite
测试随机写的I/O
顺序IO是指读写操作的访问地址顺序连接。
随机IO是指读写操作时间连续,但是访问地址不连续,随机分布在磁盘的地址空间中。
rw=randrw
测试随机写或者读的IO
rwmixwrite=int
在混合读写模式下,写占用30%
- Blocks size
bs=int
单次IO的块文件大小为16k
bsrange=1k-4k,2k-8k,1k-4k
指定数据块的大小范围,可以为读取、写入和修剪指定逗号分割的范围。
size=5G
每个线程读写的数据量是5GB
- Job description
name=str
一个任务的名字,重复了也没关系。如果fio -name=job1 -name=job2,建立了两个任务,共享-name=job1之前的参数。-name=job1之后的就是job2任务独有的参数。
numjobs=int
创建此作业的指定数量的克隆。每个作业克隆都作为一个独立的线程或者进程产生(执行相同工作的进程或者线程)。每个Job(任务)开1个线程,有多少 -name 就开多少个线程。所以最终线程数 = 任务数 (-name 的数量) * numjiobs。
filename=str
测试文件的名称。指定相对路径或者绝对路径。没有的话会自行创建。
- I/O engine
ioengine=<str>
str: sync 基本的同步·读写操作,参考fsync和fdatasync
str:psync 基于 pread(2) 或者 pwrite(2) 进行IO操作。
str:vsync
str:pvsync
str:pvsync2:
str:io_uring 快速的Linux原生异步I/O。支持直接和缓冲IO操作。
str:io_uring_cmd 用于传递命令的快速Linux本机异步I/O。
str:libaio linux异步I/O。注意:Linux可能只支持具有非缓冲I/O的排队行为
- IO depth
iodepth=int
队列的深度。在异步模式下,CPU不能一直无限的发命令到SSD。
- Buffers and memory
lockmem=int
使用mlock(2)固定指定数量的内存。可用于模拟较小的内存量。只使用指定内存进行测试。
zero_buffers
用全零初始化缓冲区。默认值:用随机数据填充缓冲区。一般使用默认值就行。
- Command line options
--output=filename
输出日志信息到指定的文件。
--output-format=format
指定输出文件的格式。
将日志格式设置为 normal、terse、json 或 json+。
可以选择多种格式,以逗号分隔。
terse 是一种基于 CSV 的格式。
json+ 类似于 json,只是它添加了延迟存储桶的完整转储。
- Reports
group_reporting
关于显示结果的,汇总每个进程的信息。
- Vertify
建议一般做读写老化过程中打开
verify=crc32c # 使用CRC32C验证
verify_fatal=1 # 遇到验证错误立即停止
verify_dump=1 # dump错误数据
verify_state_save=1 # 保存验证状态
do_verify=1 # 写入后立即验证
使用示例
测试读写速度
Test write speed io:
fio --name=write_test --filename=/path/to/testfile --size=1G --bs=4k --rw=write --ioengine=libaio --direct=1 --numjobs=1 --runtime=60 --group_reporting
Test read speed io:
fio --name=read_test --filename=/path/to/testfile --size=1G --bs=4k --rw=read --ioengine=libaio --direct=1 --numjobs=1 --runtime=60 --group_reporting
Test read and write speed io:
fio --name=rw_test --filename=/path/to/testfile --size=1G --bs=4k --rw=randrw --rwmixread=70 --ioengine=libaio --direct=1 --numjobs=1 --runtime=60 --group_reporting
测试读写老化,并进行数据校验
fio --name=randrw_test --filename=/dev/mmcblk2p6 --rw=randrw --rwmixread=70 -rwmixwrite=30 --bs=4k --size=1G --ioengine=libaio --direct=1 --numjobs=1 -runtime=24h -time_based --iodepth=32 --verify=crc32c --verify_fatal=1 --group_reporting
dd
用于快速测试顺序读写性能
使用示例
# 写顺序性能测试
dd if=/dev/zero of=./testfile bs=1G count=1 oflag=direct
# 读顺序性能测试
dd if=/dev/zero of=./testfile bs=1G count=1 oflag=direct
在测试读性能前,需要确保这个文件不在内存缓存中,需要清除缓存后再测试顺序读性能
sudo sh -c 'sync && echo 3 > /proc/sys/vm/drop_caches'
随机测试
dd命令的随机测试一般是通过 bs=4k 去模拟实际场景中的小块数据写入读出
性能问题分析工具
应用层常用工具
iostat
用途: 实时监控 I/O 负载、延迟和利用率
适用场景: 简单监控cpu使用情况和I/O性能情况和是否为瓶颈
基本语法:
iostat [选项] [时间间隔] [次数]
常见参数
| 参数 | 说明 |
|---|---|
-c | 只显示CPU利用率报告 |
-d | 只显示设备(磁盘)利用率报告 |
-x | 显示扩展的I/O统计信息(非常关键!),提供更详细的指标,如 await, svctm, util 等 |
-k | 以 KB/s 为单位显示数据(而非默认的块/s) |
-m | 以 MB/s 为单位显示数据 |
-p | 显示块设备及其所有分区的统计信息。-p ALL 显示所有设备分区 |
-t | 在输出中显示时间戳 |
-y | 跳过首次报告(系统启动以来的平均统计),直接显示间隔后的数据 |
-h | 以人类可读的格式(自动格式化单位) |
-z | 省略在采样期间无活动的设备 |
使用示例
iostat -d -k -x 1 100
Linux 6.6.63 (k1) 2025年07月04日 _riscv64_ (8 CPU)
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
mmcblk2 1.00 14.12 0.00 0.00 0.62 14.15 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.03
nvme0n1 38.22 1527.17 11.46 23.07 0.25 39.96 6.44 55.63 1.45 18.32 1.00 8.63 0.00 0.00 0.00 0.00 0.00 0.00 0.15 0.31 0.02 0.79
strace
用途: 追踪进程产生的所有系统调用,包括参数、返回值和执行消耗时间
适用场景: 程序意外退出、程序运行缓慢、进程阻塞
常用参数
使用方式
strace -f -F -T -tt -o output.txt staced_cmd
| 参数 | 说明 |
|---|---|
-f | 跟踪由 fork() 产生的子进程 |
-F | 跟踪由 vfork() 产生的子进程 |
-tt | 在输出中的每一行前加上时间欣欣,微秒级 |
-T | 显示每一个调用所耗的时间 |
-o | 输出到指定文件 |
使用示例
strace -T -tt -f -F ls
strace -T -tt -e trace=all -o output.txt -p xxx
每一行都是一条系统调用,等号左边是系统调用的函数名及参数,右边是该调用的返回值。
strace从内核接受信息,不需要以任何特殊的方式来构建内核
lsof
lsof(list open files)是一个查看当前系统文件的工具。在linux环境下,任何事物都以文件的形式存在。
常见参数
| 列名 | 含义 |
|---|---|
COMMAND | 进程名称 |
PID | 进程标识符 |
PPID | 父进程标识符(需要指定 -R 参数) |
USER | 进程所有者 |
PGID | 进程所属组 |
FD | 文件描述符,应用程序通过它识别文件 |
TYPE | 文件类型,如 DIR、REG 等 |
DEVICE | 文件所在磁盘 |
SIZE | 文件大小 |
NODE | 索引节点 |
NAME | 打开的文件名称 |
使用示例
lsof查看进程打开的文件,使用方式:
#查看文件系统阻塞
lsof /boot
#查看端口号被哪个进程占用
lsof -i : 3306
#查看用户打开哪些文件
lsof –u username
#查看进程打开哪些文件
lsof –p 4838
#查看远程已打开的网络链接
lsof –i @192.168.34.128
内核性能工具
Blktrace
Blktrace 提供 I/O 子系统的详细时间消耗信息,例如判断慢是出在 IO 调度还是硬件响应。 配套工具:
blkparse:从 blktrace 输出中读取原始日志,并生成可读的 I/O 操作摘要。btt:作为 blktrace 软件包的一部分而被提供, 分析 blkparse 输出,显示该数据用在每个 I/O 栈区域的时间消耗,便于在 I/O 子系统中发现瓶颈。
内核配置
CONFIG_FTRACE=y
CONFIG_BLK_DEV_IO_TRACE=y
常见参数
| 参数 | 作用 | 示例 |
|---|---|---|
-w <秒> | 设置采集时长 | blktrace -d /dev/sda -w 10 |
-a <事件> | 过滤事件类型(如read,write) | blktrace -d /dev/sda -a read |
-o <前缀> | 自定义输出文件名 | blktrace -d /dev/sda -o mylog |
使用示例
blktrace -d /dev/mmcblk2p6
blkparse -i mmcblk2p6 -d blkparse.out
btt -i blkparse.out
输出示例:
ALL MIN AVG MAX N
Q2Q 0.000001140 0.000029558 0.012633253 33822
D2C 0.000118989 0.003573138 0.015725019 33823
说明:
- Q2Q: 请求间隔延迟
- D2C: 驱动提交到 IO 完成的物理延迟(设备响应时间)
输出关键字段解析
| 字段 | 含义 |
|---|---|
| 设备号 | 如 8,0(主设备号 + 次设备号) |
| CPU ID | I/O 所属 CPU 核心 |
| 序列号 | I/O 请求唯一标识 |
| 时间戳 | 事件触发时间(秒) |
| 进程 ID | 发起 I/O 的进程 ID |
| 事件类型 | 核心字段:Q(IO 请求生成)、G(请求进入通用块层)、I(插入 IO 调度队列)、D(提交给设备驱动)、C(IO 完成) |
| 操作类型 | R(读)、W(写)、D(块操作) |
| 扇区信息 | 起始扇区 + 扇区数,如 223490+56 |
流程解读:
IO 请求生成(Q)→ 进入块层(G)→ 插入调度队列(I)→ 提交驱动(D)→ 完成(C)
Bpftrace
Bpftrace是基于eBPF技术的高阶追踪语言,专为Linux系统实时诊断设计。其核心优势包括:
- 动态探针: 支持内核/用户态函数无重启挂钩
- 低开销: 通过 eBPF 验证器确保安全执行
- 类C语法: 简化脚本开发流程
- 多源数据融合: 可同时捕获系统调用、性能事件等
主要应用场景
- 系统性能分析
- CPU 使用分析:跟踪进程调度、上下文切换、CPU 缓存命中率等
- 内存分析:监控内存分配/释放、页面错误、内存泄漏等
- I/O 性能:测量文件读写、磁盘 I/O 延迟等
- 网络性能�:分析网络包处理、套接字操作等
- 故障排查与调试
- 系统调用追踪:监控特定进程的系统调用及其参数
- 函数调用跟踪:记录特定函数的调用路径和参数
- 异常行为检测:识别异常的系统调用模式或错误返回值
探针类型
| 类型 | 描述 | 示例 |
|---|---|---|
| kprobe | 内核函数入口 | kprobe:vfs_read |
| uprobe | 过滤事件类型(如read,write) | uprobe:/bin/bash:readline |
| tracepoint | 静态跟踪点 | tracepoint:syscalls:sys_enter_openat |
| interval | 定时触发 | interval:s:5(每 5 秒执行一次) |
Kprobe
配置
CONFIG_KPROBES
CONFIG_HAVE_KPROBES
CONFIG_KPROBE_EVENTS
使用示例
获取函数的偏移
bpftrace -e 'kprobe:do_sys_open+9 {printf("in here);}'
获取 sys_read() 运行时间
- 支持添加过滤条件,可以记录调用上下文信息,如进程名,参数等
- bpftrace 的这种时间测量方法相比 ftrace 等工具更加精确,能够提供纳秒级的时间分辨率
#!/usr/bin/bpftrace
BEGIN {
printf("Tracing sys_read execution time... Hit Ctrl-C to end.\n");
}
kprobe:sys_read
{
@start[tid] = nsecs;
}
kretprobe:sys_read
/@start[tid]/
{
$duration = nsecs - @start[tid];
@times = hist($duration / 1000); // 转换为微秒
delete(@start[tid]);
}
END {
printf("\nSys_read execution time distribution (us):\n");
print(@times);
}
Uprobe
配置
CONFIG_UPROBE
ARCH_SUPPORT_UPROBES
CONFIG_UPROBE_EVENTS
使用示例
统计程序每次执行的时间
bpftrace -e 'BEGIN {@ts = nsecs} uprobe:./example:test {$lat=nsecs - @ts; printf("%s: duration at %d is %d\n", comm, arg0,
$lat); @ts=nsecs}'
Attaching 2 probes...
example: duration at 1 is 657420674
example: duration at 2 is 105863
example: duration at 3 is 16843
example: duration at 4 is 9517
example: duration at 5 is 8882
example: duration at 6 is 9386
example: duration at 7 is 10101
example: duration at 8 is 10086
example: duration at 9 is 10005
example: duration at 10 is 10003
example: duration at 1 is 1000382292
...
文件访问监控
# 跟踪文件打开操作(含进程名和文件名)
bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s -> %s\n", comm, str(args.filename)); }
系统调用统计
# 按进程统计系统调用次数
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
测量 vfs_read 调用时间分布
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Attaching 2 probes...
[...]
@ns[snmp-pass]:
[0, 1] 0 | |
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 0 | |
[16, 32) 0 | |
[32, 64) 0 | |
[64, 128) 0 | |
[128, 256) 0 | |
[256, 512) 27 |@@@@@@@@@ |
[512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1k, 2k) 22 |@@@@@@@ |
[2k, 4k) 1 | |
[4k, 8k) 10 |@@@ |
[8k, 16k) 1 | |
[16k, 32k) 3 |@ |
[32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[64k, 128k) 7 |@@ |
[128k, 256k) 28 |@@@@@@@@@@ |
[256k, 512k) 2 | |
[512k, 1M) 3 |@ |
[1M, 2M) 1 | |
bpftrace vs strace
| 特性 | bpftrace | strace |
|---|---|---|
| 跟踪层级 | 内核/用户空间任意函数 | 仅系统调用层面 |
| 性能影响 | 低开销 | 较高开销 |
| 功能范围 | 自定义复杂跟踪逻辑 | 固定系统调用跟踪 |
| 使用复杂度 | 需要编写脚本 | 命令行直接使用 |
Perf
Perf 是用来进行 软件性能分析 的工具。
- 性能统计:应用程序可以利用 PMU、tracepoint 和内核中的特殊计数器进行性能监控。
- 分析能力:
- 指定应用程序的性能问题(per thread)
- 内核性能问题
- 同时分析应用代码和内核,全面理解应用程序的性能瓶颈
- 程序运行期间的硬件事件
- 程序运行期间的软件事件,如 Page Fault、进程切换、cache miss 等
- 其他功能:
- 计算 IPC
- 可替代 strace 进行系统调用追踪
- 支持添加动态内核 probe 点
- 用于 benchmark,评估调度器性能
常用参数
| 参数 | 功能说明 |
|---|---|
stat | 显示简要的性能统计信息,包括 CPU 周期、指令数、缓存命中率等 |
perf list | 列出可用的性能事件和计数器 |
record | 记录性能事件并生成数据文件,用于后续分析 |
top | 显示正在运行的进程和函数的性能统计信息,类似 top 命令 |
report | 对数据文件进行分析并生成性能报告 |
annotate | 将源代码与性能分析结果关联,便于源代码级分析 |
perf record -e <event> | 记录指定的性能事件 |
perf record -p <pid> | 记录指定进程的性能事件 |
perf record -a | 记录系统范围的性能事件 |
perf report -n | 生成性能报告,不依赖源代码 |
使用示例
- 查看 Cache 命中率 通过此示例可以快速了解 CPU 缓存的使用情况和效率:
perf stat -e l1d_load_access,l1d_load_miss,l1i_load_access,l1i_load_miss,l2_load_miss,l2_load_access -p 3014 sleep 2
Performance counter stats for process id '3014':
50,436,940 l1d_load_access #6.42% of all L1-dcache accesses
3,136,603 l1d_load_miss
768,043,161 l1i_load_access
5,217,676 l1i_load_miss
5,227,730 l2_load_miss #44%
11,883,914 l2_load_access
2.006649641 seconds time elapsed
- 实时显示当前系统的性能统计信息
perf top
- 用于实时监控系统的性能,显示每个特定功能使用的 CPU 时间。
- 在默认模式下,统计 用户态程序 和 内核态函数 在所有 CPU 上的执行情况。
- 该命令主要用来观察整个系统当前的状态,例如可以通过查看该命令的输出,快速找到 系统中最耗时的内核函数或用户进程,有助于发现性能瓶颈。
perf top -e cpu-clock
- 显示程序或进程的汇总性能统计
perf stat
- 通过概括精简的方式提供被调试程序运行的整体情况和汇总数据
perf stat -p 6421
Performance counter stats for process id '6421':
37,059.60 msec task-clock # 1.354 CPUs utilized
29,052 context-switches # 783.927 /sec
1,011 cpu-migrations # 27.280 /sec
141 page-faults # 3.805 /sec
58,635,997,124 cycles # 1.582 GHz
9,428,213,699 instructions # 0.16 insn per cycle
1,000,575,638 branches # 26.999 M/sec
74,397,683 branch-misses # 7.44% of all branches
27.378870476 seconds time elapsed
- 记录函数级别的性能事件
perf record
- 记录单个函数级别的统计信息,并使用
perf report来显示统计结果。
参数解释:
-F 99:1秒钟进行采集99次-a:采集所有 CPU 信息
perf record -e cpu-clock
# 停止采集时输出
^C[ perf record: Woken up 72 times to write data ]
[ perf record: Captured and wrote 19.862 MB perf.data (349631 samples) ]
- 分显示统计结果
perf report
- 执行
perf record之后在当前目录下会生成一个perf.data文件,可通过perf report可以读取perf.data文件并在终端中展示。
Samples: 349K of event 'cpu-clock', Event count (approx.): 87407750000
Overhead Command Shared Object Symbol
14.34% swapper [kernel.kallsyms] [k] default_idle_cal
3.64% stress-ng-cpu libgcc_s.so.1 [.] __multf3
2.52% stress-ng-cpu libm.so.6 [.] __multf3
1.70% stress-ng-cpu libgcc_s.so.1 [.] __addtf3
1.53% glmark2-es2-way libc.so.6 [.] memmove
1.17% swapper [kernel.kallsyms] [k] finish_task_swit
0.79% stress-ng-cpu libm.so.6 [.] __addtf3
0.74% gnome-system-mo libpixman-1.so.0.42.2 [.] 0x000000000002c4
0.66% stress-ng-cpu libm.so.6 [.] __subtf3
0.57% glmark2-es2-way glmark2-es2-wayland [.] WaveMesh::update
0.52% fio [kernel.kallsyms] [k] finish_task_swit
0.42% gnome-shell libc.so.6 [.] memcpy
0.38% mpv [kernel.kallsyms] [k] arch_sync_dma_fo
0.30% stress-ng-cpu libm.so.6 [.] __sqrtl_finite@G
0.29% stress-ng-cpu libgcc_s.so.1 [.] __divtf3
0.26% mpv/vo [kernel.kallsyms] [k] arch_sync_dma_fo
0.24% fio fio [.] get_io_u
0.23% gnome-system-mo libcairo.so.2.11800.0 [.] 0x000000000002de
0.23% chrome libc.so.6 [.] memcpy
0.23% ThreadPoolForeg chrome [.] 0x0000000005457b
0.23% chrome [kernel.kallsyms] [k] finish_task_swit
bpftrace vs perf
| 特性 | bpftrace | perf |
|---|---|---|
| 数据采集 | 基于事件触发 | 基于采样 |
| 编程能力 | 支持复杂脚本编程 | 有限的自定义能力 |
| 分析深度 | 可深入函数内部逻辑 | 主要关注调用频率 |
| 可视化 | 内置直方图等统计功能 | 依赖外部工具生成火焰图等 |
文件系统常见的异常
文件系统变为只读 (Read-only Filesystem)
这是最常见的一种保护性异常。
表现:无法创建新文件、无法修改或删除现有文件,系统提示 Read-only file system。
排查步骤
- 排除本次启动之前是否发生意外断电
- 如果发生意外断电,可手动调用对应的文件系统修复工具扫描并修复文件系统,保证元数据一致。
- 对于 SD 卡、U 盘等支持热插拔的设备尤其常见。
- 排除是否有主存错误
- 可通过
dmesg,查看系统 log 是否有除文件系统读写报错以外的存储驱动报错
解决方案
- 手动使用
fsck修复文件系统
基本命令语法:
sudo fsck [选项] <设备名>
常用选项:
-p:自动修复所有安全的错误(不询问)。这是默认行为之一,但可能不会修复所有问题。-y / --yes:对所有询问自动回答 "yes"。这是最常用的强制修复选项。-n:只检查文件系统,而不进行任何修复。-f:强制检查,即使文件系统看起来是干净的。-v: verbose 模式,输出详细过程。-C:显示进度条(仅对 ext2/3/4 文件系统有效)
- 处理存储驱动报错
如果检查 log 中发现存储驱动报错,如mmc0,mmc2,usb等驱动报错
- 查看对应的驱动说明文档,查看FAQ中是否有类似的问题解决方法。
- 如果是 SD 卡 或者 USB 等外部存储设备,建议更换设备,确认是否硬件异常。
挂载失败
找不到指定的IO字符集
报错示例如下
mount -t vfat /dev/block/vol-179-33 /mnt/data/external/8461-3631 <
[ 562.455742] FAT-fs (mmcblk0p1): IO charset iso8859-1 not found
解决方案
步骤 1:检查是否配置相应字符集
zcat /proc/config.gz | grep CONFIG_NLS_ISO8859_1
步骤2:在内核 menuconfig 中配置相应字符集
-> File systems
-> Native language support (NLS [=y])
-> NLS ISO 8859-1 (Latin 1; Western European Languages)(NLS_IS08859_1 [=y])
磁盘空间不足 (No Space Left on Device)
表现: 无法写入文件
系统报错: No space left on device
可能原因:
- 磁盘块 (Block) 用尽:
- 使用
df -h检查发现某个分区的使用率是 100%。
- 索引节点 (Inode) 用尽:
- 磁盘可能还有剩余空间,但存放文件元信息(如文件名、权限、时间戳)的 Inode 表已满。
- 常见于存在大量小文件(如邮件、缓存文件)的系统。
- 可使用
df -i检查 Inode 使用情况。
开机或其他老化场景Oops
Oops非法指令
[ 135.238092] Oops - illegal instruction [#1]
[ 135.238110] Modules linked in: husb239 typec 8852bs
[ 135.238127] CPU: 3 PID: 2787 Comm: distribute#1 Not tainted 6.6.36 #1
[ 135.238137] Hardware name: M1-MUSE-PAPER2 (DT)
[ 135.238142] epc : close_fd_get_file+0x2/0x46
[ 135.238162] ra : __riscv_sys_close+0x10/0x60
[ 135.238171] epc : ffffffff8024759a ra : ffffffff80224a84 sp : ffffffc80a05bea0
[ 135.238176] gp : ffffffff82302708 tp : ffffffd961e0b300 t0 : ffffffff80ffc052
[ 135.238180] t1 : ffffffff816011b0 t2 : ffffffff81601230 s0 : ffffffc80a05bec0
[ 135.238185] s1 : ffffffc80a05bf30 a0 : 0000000000000024 a1 : 0000000000000000
[ 135.238188] a2 : 0000000000000000 a3 : 0000000300000000 a4 : 0000000200000000
[ 135.238191] a5 : ffffffff80224a74 a6 : 0000003f8947f2d4 a7 : 0000000000000039
[ 135.238196] s2 : 0000003f8a2e2c70 s3 : 0000000000000000 s4 : 0000000000000008
[ 135.238199] s5 : 0000003f8947faf8 s6 : 0000000000000000 s7 : 0000000100000000
[ 135.238202] s8 : ffffffffffffffff s9 : 0000003f8978a010 s10: 7fffffffffffffff
[ 135.238205] s11: 8000000000000000 t3 : 0000003f8a2e2da8 t4 : 0000000000000010
[ 135.238208] t5 : 000000000147ae14 t6 : ffffffffffff7fff
[ 135.238211] status: 0000000200000120 badaddr: 000000000904ff07 cause: 0000000000000002
[ 135.238216] [<ffffffff8024759a>] close_fd_get_file+0x2/0x46
[ 135.238225] [<ffffffff80ffc10c>] do_trap_ecall_u+0xba/0x12e
[ 135.238238] [<ffffffff81005582>] ret_from_exception+0x0/0x6e
[ 135.238251] Code: ff05 0a04 ff05 0a04 ff05 0904 ff07 0904 ff07 0904 (ff07) 0904
[ 135.238259] ---[ end trace 0000000000000000 ]---
[ 135.238263] Kernel panic - not syncing: Fatal exception in interrupt
[ 135.238266] SMP: stopping secondary CPUs
[ 135.392375] ---[ end Kernel panic - not syncing: Fatal exception in interrupt ]---
上述非法指令表现为在linux核心层,甚至表现为随机异常,启动多次对应的堆栈不同
排查步骤
-
检查 DDR 容量配置是否正确
- 对于全新的板子, 请确认板子上使用的 DDR size 是否与启动过程中现实的 size 一致。
- 如果 size 不一致,需要烧号工具重新烧写 CS 值,以保证正确配置 DDR
-
验证 DDR 稳定性(新板重点关注)
- 使用
memtest压测 DDR,排除 DDR 稳定性问题。 - SpacemiT 内部有闭源的裸机 DDR 测试工具,如需要可以联系 AE 获取。
- 使用
-
检查 Image 是否完整(升级或手动刷机后重点关注)
- 确认手动安装后是否调用 reboot 重启。
- 如果存在直接掉电或者使用
reboot -f重启,可能会导致数据在文件系统缓存中,没有被安全完整的写入主存中。
-
确认U-Boot 加载 Image 地址是否异常
- 如下 log 显示 Image 被加载到物理地址起始
0x600000~0x2786000,建议启动 cmdline 中memblock=debug,查看内核预留内存是否有与这段地址冲突。
- 如下 log 显示 Image 被加载到物理地址起始
No FDT memory address configured. Please configure
the FDT address via "fdt addr <address>" command.
Aborting!
[ 1.719] Moving Image from 0x200000 to 0x600000, end=2786000
[ 1.740] ## Flattened Device Tree blob at 31000000
[ 1.741] Booting using the fdt blob at 0x31000000
[ 1.746] Loading Ramdisk to 7d8b8000, end 7dd7dee7 ... OK
[ 1.759] Loading Device Tree to 000000007d89f000, end 000000007d8b793f ... OK
使能memblock试信息的方式常用的有3种
- 修改
bootfs分区的env_k1-x.txt,添加memblock=debug后重启 - 进入
uboot shell,通过env set重新设置bootargs,添加`memblock=debug`` - 修改内核
dtsi,在bootargs中添加memblock=debug,这个方式需要重新编译内核
解决方案
-
DDR 容量配置异常
- 需要通过烧号工具重新写 CS 值,保证容量识别正常。
- 写号工具集成到刷机工具中,参考:工具链接
-
DDR 稳定性异常(memtest 不通过)
- 检查 DDR 是否在 SpacemiT 官方支持列表中。
- 如果不在,请使用在支持列表中的物料,或者将 DDR 型号告诉 SpacemiT,待压测入支持列表后继续使用。
- 支持列表查询:DDR 支持列表
-
更新后异常重启
- 建议通过 U-Boot shell 修改 env, 选择上一个版本的 Image 加载。
- 正常进入系统后,重新安装 deb 包或者升级,并执行
sync确保数据落盘。 - 最后运行
reboot重启,让新的 Image 正常生效。
-
Image 加载地址异常
- 通过
memblock debug确认冲突的地址。 - 通过调整 Image 加载地址解决问题:
- Bianbu OS 使用 非 FIT 格式 加载 Image,需要通过 Linux
menuconfig配置CONFIG_IMAGE_LOAD_OFFSET调整
- Bianbu OS 使用 非 FIT 格式 加载 Image,需要通过 Linux
- 通过
Symbol: IMAGE_LOAD_OFFSET [=0x600000]
│ Type : hex
│ Defined at arch/riscv/Kconfig:1072
│ Prompt: Image load offset from start of RAM when load kernel to RAM
│Location:
│ (1) -> Image load offset from start of RAM when load kernel to RAM (IMAGE_LOAD_OFFSET [=0x600000])
Oops地址异常
Unable to handle kernel paging request at virtual address ffffffdb33e98040
[ 87.422523] systemd-journal[382]: unhandled signal 4 code 0x1 at 0x0000003f9c21ec1e in libsystemd-shared-255.so[3f9c000000+33b000]
[ 87.422561] CPU: 6 PID: 382 Comm: systemd-journal Not tainted 6.6.63 #2.2~beta1.2+20250325010730
[ 87.422568] Hardware name: spacemit k1-x MUSE-Pi-Pro board (DT)
[ 87.422572] epc : 0000003f9c21ec1e ra : 0000003f9c2089ce sp : 0000003fe8845980
[ 87.422576] gp : 0000002abe00e800 tp : 0000003f9bbce780 t0 : 000000003d454741
[ 87.422580] t1 : 0000003f9c06d9dc t2 : 4f4e4f4d5f454352 s0 : 0000003fe8845ab0
[ 87.422584] s1 : 000000000000000a a0 : 0000003fe8845a18 a1 : 0000003f9bbcf100
[ 87.422587] a2 : 0000000000000001 a3 : ffffffffffffffff a4 : fffffffffffff8d0
[ 87.422590] a5 : 6515380c376e55a9 a6 : 0000003f9c453000 a7 : 0000000000000000
[ 87.422594] s2 : 0000003fe8845af0 s3 : 0000003fe8845a28 s4 : 0000000000000000
[ 87.422598] s5 : 0000002abe017280 s6 : 0000003fe8845a18 s7 : 0000003f9c47dd08
[ 87.422602] s8 : 000000000534c50e s9 : 0000003fe8845a28 s10: 0000003fe8845c20
[ 87.422605] s11: 0000000000000000 t3 : 0000003f9c466aa8 t4 : ffffffffffffffff
[ 87.422609] t5 : 000000009aa8aa71 t6 : 0000003fe8847ad0
[ 87.422612] status: 0000000200004020 badaddr: 0000000000000000 cause: 0000000000000002
[ 87.423783] apport[2790]: unhandled signal 4 code 0x1 at 0x0000003fb82236d2 in ld-linux-riscv64-lp64d.so.1[3fb820f000+22000]
[ 87.423827] CPU: 4 PID: 2790 Comm: apport Not tainted 6.6.63 #2.2~beta1.2+20250325010730
[ 87.423834] Hardware name: spacemit k1-x MUSE-Pi-Pro board (DT)
[ 87.423838] epc : 0000003fb82236d2 ra : 0000003fb821f9f8 sp : 0000003fc88dbc00
[ 87.423843] gp : 0000000000000000 tp : 0000000000000000 t0 : 0000000000000000
[ 87.423847] t1 : 0000003fb820d000 t2 : 0000000000000000 s0 : 0000003fc88dbc50
[ 87.423852] s1 : 0000003fb8220c10 a0 : 0000000000000000 a1 : 0000003fc88dbbec
[ 87.423855] a2 : 0000000000000000 a3 : 0000003fb8232228 a4 : 0000003fb8232ae0
[ 87.423859] a5 : 0000000000000001 a6 : 0000000000000000 a7 : 0000000000000002
[ 87.423863] s2 : 0000003fb8232d10 s3 : 0000003fb8232cd8 s4 : 0000003fb820f000
[ 87.423867] s5 : 0000000000000005 s6 : 0000000000000002 s7 : 0000003fb820f000
[ 87.423872] s8 : 0000003fb8234008 s9 : 0000000000000000 s10: 0000003fb820f388
[ 87.423876] s11: 0000000000000003 t3 : 0000000000000440 t4 : 0000000000000000
[ 87.423880] t5 : 0000000000000064 t6 : 0000000000000000
[ 87.423883] status: 0000000200004020 badaddr: 0000000000000000 cause: 0000000000000002
排查步骤
-
检查 DDR 容量配置是否正确
- 对于全新的板子, 请确认板子上使用的 DDR size 是否与启动过程中现实的 size 一致。
- 如果 size 不一致,需要烧号工具重新烧写 CS 值,以保证正确配置 DDR
-
验证 DDR 稳定性(新板重点关注)
- 使用
memtest压测 DDR,排除 DDR 稳定性问题。 - SpacemiT 内部有闭源的裸机 DDR 测试工具,如需要可以联系 AE 获取。
- 使用
-
确认是否为内核原生代码问题
- 如果跑飞的堆栈是是内核原生代码, 建议先开启内核内存 debug,开启调试工具 KASAN(Kernel Address Sanitizer),排查潜在的内存非法访问风险。
- 如果有驱动报错,可反馈给 SpacemiT 进一步分析处理。
解决方案
-
DDR 容量配置异常
- 需要通过烧号工具重新写 CS 值,保证容量识别正常。
- 写号工具集成到刷机工具中,参考:工具链接
-
DDR 稳定性异常(memtest 不通过)
- 检查 DDR 是否在 SpacemiT 官方支持列表中。
- 如果不在,请使用在支持列表中的物料,或者将 DDR 型号告诉 SpacemiT,待压测入支持列表后继续使用。
- 支持列表查询:DDR 支持列表
-
开启 KASAN 检测内存问题
- 使能 KASAN,配置
KASAN=Y后编译运行
- 使能 KASAN,配置
Symbol: KASAN [=n]
│ Type : bool
│ Defined at lib/Kconfig.kasan:34
│ Prompt: KASAN: dynamic memory safety error detector
│ Depends on: ((HAVE_ARCH_KASAN [=y] && CC_HAS_KASAN_GENERIC [=y] || HAVE_ARCH_KASAN_SW_TAGS [=n] && CC_HAS_KASAN_SW_TAGS [=n]) && CC_HAS_WORKING_NOSANITIZ
│ Location:
│ -> Kernel hacking
│ -> Memory Debugging
│ (1) -> KASAN: dynamic memory safety error detector (KASAN [=n])
│ Selects: STACKDEPOT_ALWAYS_INIT [=n]
检测到如 BUG: KASAN: global-out-of-bounds 等异常,可以附上 log,提单给 SpacemiT 解决
注意: KASAN对性能影响较大,建议仅在 debug 场景打开,其他场景默认关闭
swiotlb full导致部分场景异常
当内存地址超出设备可访问范围(如 USB 或存储模块),且硬件 IP 不一定能直接访问该地址时,这个时候需要 SWIOTLB 拷贝一次数据。不过,这会影响性能。 SpacemiT 预留 128 MB SWIOTLB。
swiotlb full 异常 log
spacemit-k1xvi c0230000.vi: swiotlb buffer is full (sz: 1048576 bytes), total 65536 (slots), used 498 (slots)
排查步骤
使用 trace event 查看都有谁使用了 swiotlb
步骤 1: 挂载 tracefs
sudo mount -t debugfs none /sys/kernel/debug
步骤 2: 使能 swiotlb event
cd /sys/kernel/tracing/
echo 1 > events/swiotlb/enable
这个trace event可以支持过滤
步骤 3: 查看 trace 日记
cat trace
示例输出:
disp_eng_share_-1439 [000] ..... 197.644246: swiotlb_bounced: dev_name: d4280800.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4 NORMAL
disp_eng_share_-1439 [000] ..... 197.644264: swiotlb_bounced: dev_name: d4280800.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4 NORMAL
jbd2/mmcblk2p6--289 [006] ..... 197.926040: swiotlb_bounced: dev_name: d4281000.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4096 NORMAL
jbd2/mmcblk2p6--289 [006] ..... 197.926052: swiotlb_bounced: dev_name: d4281000.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4096 NORMAL
jbd2/mmcblk2p6--289 [006] ..... 197.926055: swiotlb_bounced: dev_name: d4281000.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4096 NORMAL
jbd2/mmcblk2p6--289 [006] ..... 197.926059: swiotlb_bounced: dev_name: d4281000.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4096 NORMAL
kworker/6:1H-76 [006] ..... 197.930374: swiotlb_bounced: dev_name: d4281000.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4096 NORMAL
ksdioirqd/mmc1-1416 [005] ..... 199.158983: swiotlb_bounced: dev_name: d4280800.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4 NORMAL
ksdioirqd/mmc1-1416 [005] ..... 199.159042: swiotlb_bounced: dev_name: d4280800.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4 NORMAL
ksdioirqd/mmc1-1416 [005] ..... 199.159071: swiotlb_bounced: dev_name: d4280800.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=212 NORMAL
ksdioirqd/mmc1-1416 [005] ..... 199.159111: swiotlb_bounced: dev_name: d4280800.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4 NORMAL
disp_eng_share_-1439 [000] ..... 199.653920: swiotlb_bounced: dev_name: d4280800.sdh dma_mask=ffffffff dev_addr=ffffffffffffffff size=4 NORMAL
上述trace event可以动态检测swiotlb的使用动态,包括谁用的,使用了多少
解决方案
检查报错的驱动是否正确设置了 dma_mask。
- 如果驱动未显式调用
coherent_dma_mask()或dma_set_mask_and_coherent(),系统会使用默认的 32-bit 配置。 - 当驱动与其他模块进行数据传输时,如果所需 DMA 地址超出驱动能力范围,系统会使用 SWIOTLB 进行一次数据拷贝,占用预留的 128MB SWIOTLB 内存。
例如,可以在驱动中新增如下设置:
+ ret = dma_set_mask_and_coherent(&pdev->dev, DMA_BIT_MASK(33));
+ if (ret)
+ return ret;